Tuning Flink for Robustness and Performance - Stefan Richter
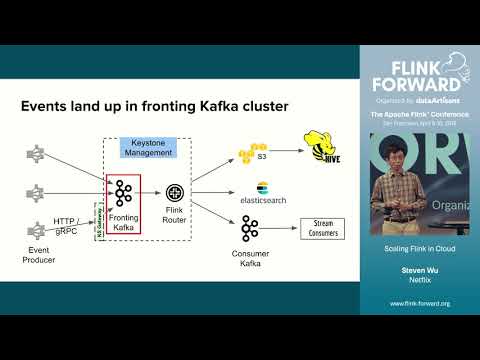
Scaling Flink in Cloud - Steven Wu
Demystifying Flink Memory Allocation and tuning - Roshan Naik
Sources, Sinks, and Operators: A Performance Deep Dive
What's new in Apache Flink 1.16
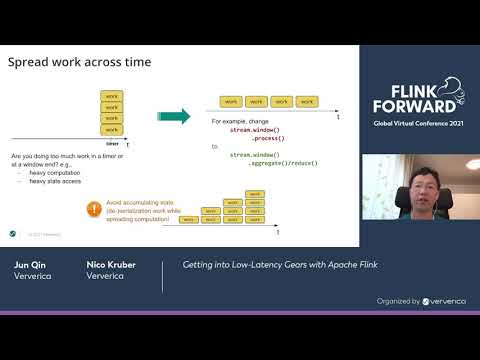
Getting into Low-Latency Gears with Apache Flink
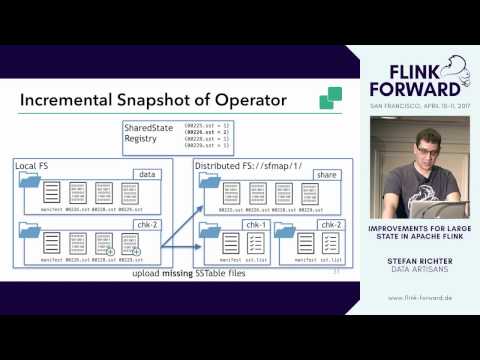
#FlinkForward SF 2017: Stefan Richter - Improvements for large state and recovery in Flink
dA Platform – Production-ready stream processing with Apache Flink - Robert Metzger & Patrick Lucas
Towards Flink 2.0: Rethinking the stack and APIs to unify Batch & Stream - Stephan Ewen & Aljoscha K
Table Tuning for Apache Iceberg - Table Properties Explained (Course #8)
Deploying a secured Flink cluster on Kubernetes - Edward Alexander Rojas Clavijo
Our successful journey with Flink - Lasse Nedergaard
How to build a modern stream processor: The science behind Apache Flink - Stefan Richter
Webinar - The Top 5 Mistakes Deploying Flink
FFA 2019 核心技术:New Features and Improvements on State Backends for Flink 1.10
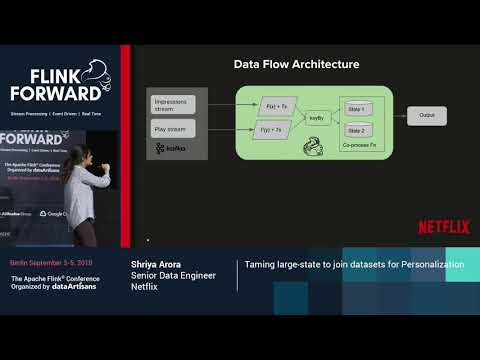
Taming large-state to join datasets for Personalization - Shriya Arora
Moving on from RocksDB to something FASTER - Matthew Brookes
Bootstrapping State In Apache Flink - Gregory Fee
FlinkNDB : Skyrocketing Stateful Capabilities of Apache Flink
Rundown of Flink's Checkpoints
Automating Flink Deployments to Kubernetes - Marc Rooding & Niels Dennissen
Stream Loops on Flink: Reinventing the wheel for the streaming era - Paris Carbone
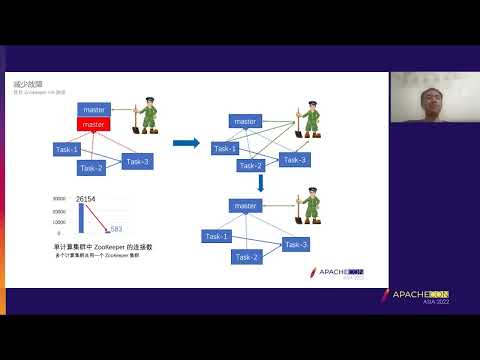
Optimization Practice Of Apache Flink Stability In Large Cluster
Towards a Flink Autopilot in Ververica Platform
Zero-downtime upgrades of Flink applications