So long Hadoop - moving data platforms to Kubernetes • Erik Schmiegelow
So Long Hadoop - Running Spark On Kubernetes by Erik Schmiegelow
Watch How This 3-Part Hadoop Solution Revolutionizes Data Management!
Storing and processing data in Hadoop by JACEK JURASZEK & JAROSLAW GRABOWSKI at Big Data Spain 2014
What is MapReduce♻️in Hadoop🐘| Apache Hadoop🐘
Colocate Hadoop YARN with Kubernetes to Save Massive Costs on Big Data - Irvin Lim & Hailin Xiang
A Hybrid Container Cloud With Kubernetes and Hadoop YARN - Jian He & Bushuang Gao, Alibaba
What Is Apache Spark?
Escaping the Hadoop Trap - Apache Iceberg as Your Data Platform's Long Term Technical Debt Shield
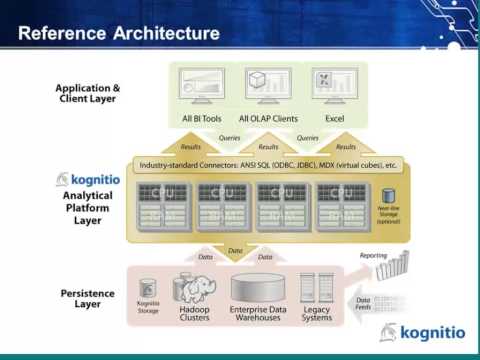
MetaScale-Kognitio Hadoop Webinar
Apache Spark - The Ultimate Guide [From ZERO To PRO]
Spark UI Explained Spotting Bottlenecks & Optimizing Speed #apachespark #dataengineering
Storm as an ETL Engine to Hadoop
Implementing AppSystem for Apache Hadoop
What is the Difference Between Spark & Hadoop
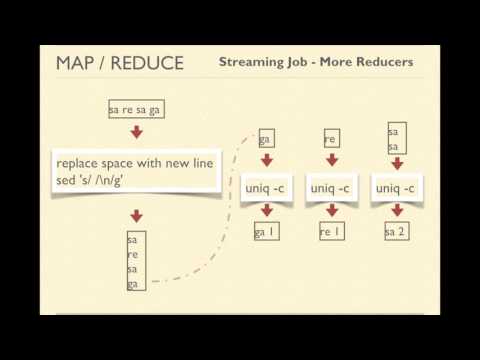
8.5. Mapreduce Programming | Run MapReduce Jobs Using Hadoop Streaming
Enterprise Challenges to Hadoop Implementation at Big Data Week Chicago
The Microsoft Big Data Stack by Raghu Ramakrishnan, CTO for Data, Microsoft
Fast SQL on Hadoop, Really?
Bringing Long Running Services to Hadoop YARN
[Blog] Is MapReduce Dead
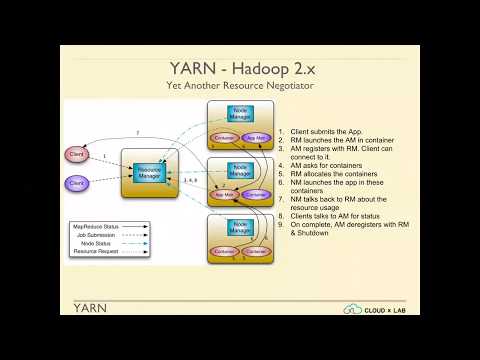
Introduction to YARN and MapReduce | Big Data Hadoop Spark | CloudxLab
Big Data In 5 Minutes | What Is Big Data?| Big Data Analytics | Big Data Tutorial | Simplilearn
A whirlwind tour through lingual: ANSI SQL for apache hadoop
Your Big Data Stack is Too Big! - Timothy Potter, Lucidworks









![Apache Spark - The Ultimate Guide [From ZERO To PRO]](https://img.youtube.com/vi/FNJze2Ea780/0.jpg)







![[Blog] Is MapReduce Dead](https://img.youtube.com/vi/OCviI0eNaiM/0.jpg)