SREcon20 Americas - Why SREs can't afford to NOT do Chaos Engineering
SREcon20 Americas - The Secret Lives of SREs - Controlling the Costs of Coordination across Remote
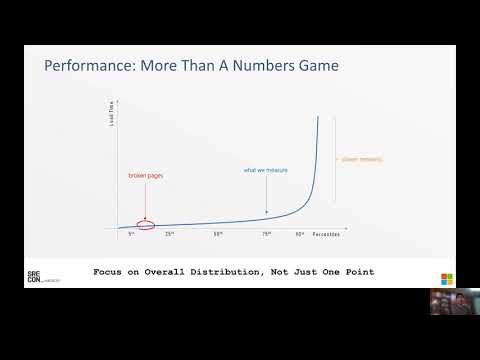
SREcon20 Americas - Capacity Planning and Performance Enhancement with Page Reference Sampling
SREcon20 Americas - Challenges of Starting an SRE Team from Scratch in an Enterprise
SREcon20 Americas - It's a Trap! How Abstractions Have Failed Us.
SREcon20 Americas - Off the Beaten Path: Moving Observability Focus from Your Service
SREcon20 Americas - SREs at Telecom and Media Industry: Bridging between Legacy and Cloud Native App
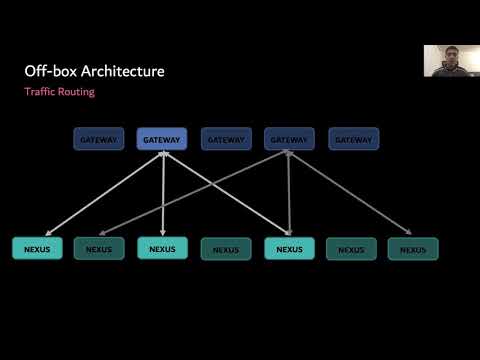
SREcon20 Americas - The Evolution of Traffic Routing in a Streaming World
SREcon20 Americas - The Smallest Possible SRE Team
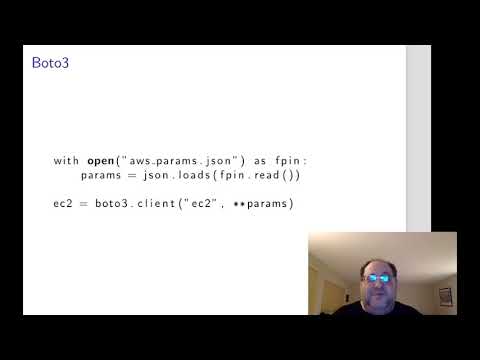
SREcon20 Americas - Making Infrastructure More Friendly for Beginners
SREcon20 Americas - Latency and Availability Error Budgets Done Right at Scale
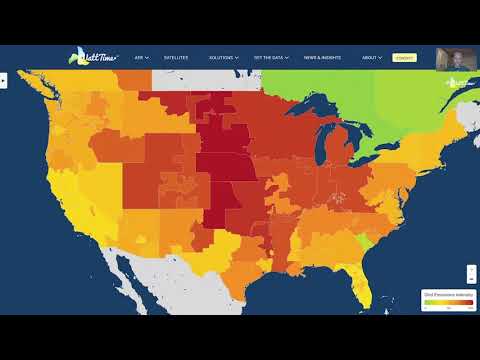
SREcon20 Americas - A Bartender's Guide to Network Monitoring
SREcon20 Americas - Observing from Incidents
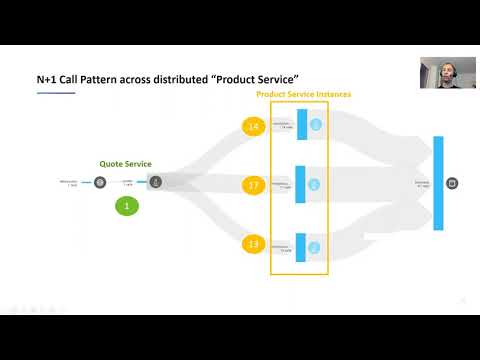
SREcon20 Americas - Identifying Hidden Dependencies
SREcon20 Americas - Cloudy with a Chance of Chaos
SREcon20 Americas - Automatically Detect the Top Performance & Scalability Issues in Distributed
SREcon20 Americas - Hot Swap Your Datastore: A Practical Approach and Lessons Learned
SREcon20 Americas - Jupyter as Incident Response Tool
SREcon20 Americas - Sustainable Software Engineering & SREs
SREcon20 Americas - Testing Encyclopedias in Production