Running Flink Data-Connectors at Scale - Vipul Singh
Apache Flink Best Practices! Best Practices for Running Apache Flink in Production!
The Flink Runtime | Apache Flink 101
High-Quality Performant and Cost Efficient Schema-Aware Data Streams on Flink at Netflix Scale
Towards Flink 2.0: Rethinking the stack and APIs to unify Batch & Stream - Stephan Ewen & Aljoscha K
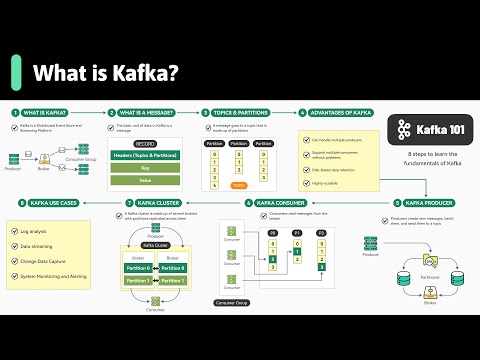
Apache Kafka Fundamentals You Should Know
Powering Yelp’s Data Pipeline Infrastructure with Apache Flink - Enrico Canzonieri
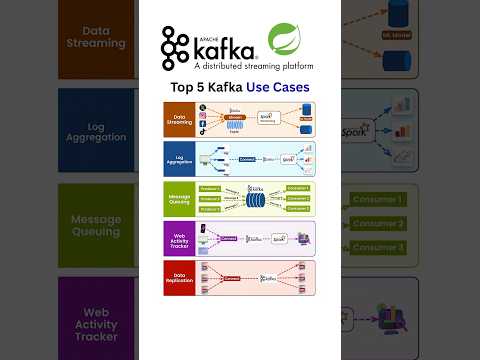
Top 5 Apache Kafka Use Cases in 2025
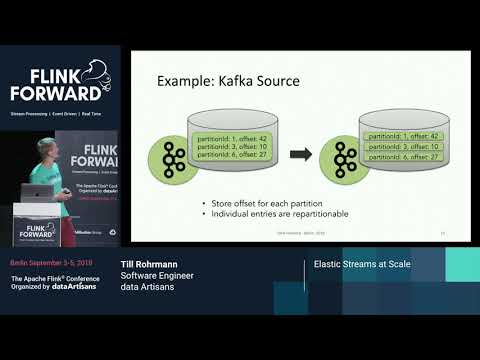
Elastic Streams at Scale - Till Rohrmann & Joerg Schad
Scaling Uber’s Realtime Optimization with Apache Flink - Xingzhong Xu
Sources, Sinks, and Operators: A Performance Deep Dive
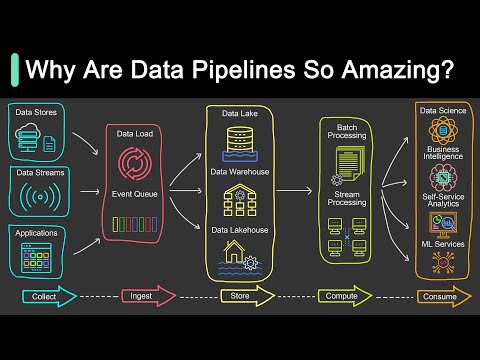
What is Data Pipeline? | Why Is It So Popular?
Apache Flink-51 Flink Source Connector Mongodb Source Connector
Operating Flink on Mesos at Scale - Jörg Schad & Biswajit Das
Apache Flink-46 Flink Source Connector DataGenerator Source Connector
Scaling stream data pipelines - Till Rohrmann & Flavio Junqueira
Apache Flink-55 Flink Source Connector Customize Source ConnectorRichSourceFunction
#FlinkForward SF 2017: Stephan Ewen - Experiences running Flink at Very Large Scale
PubSub - Simplest Explanation Ever! Kafka, RabbitMQ - Must Know HLD Topics!
Apache Flink-44 Flink Source Connector Introduction