Powering Yelp’s Data Pipeline Infrastructure with Apache Flink - Enrico Canzonieri
Stream SQL with Flink @ Yelp - Enrico Canzonieri
Elastic Data Processing with Apache Flink and Apache Pulsar - Sijie Guo
Building Stateful Streaming Pipelines - Ankit Jhalaria
Berlin Buzzwords 2016: Enrico Canzonieri - Scaling Yelp’s Logging Pipeline with Apache Kafka #bbuzz
Flink SQL Powered AutoML Pipeline - Wei Wang & Hao Wu
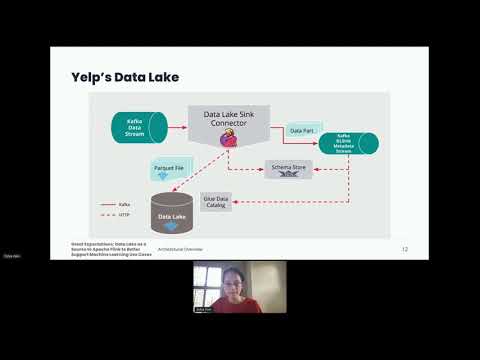
Data Lake as Source to Apache Flink to Better Support Machine Learning Use Cases - S. Irwin, C. Tan
FlinkNDB : Skyrocketing Stateful Capabilities of Apache Flink
Enriching your Data Stream Asynchronously with Apache Flink
Building Self Service Platforms for Apache Flink - Canzonieri & Novak & Gorman & Nienhuis
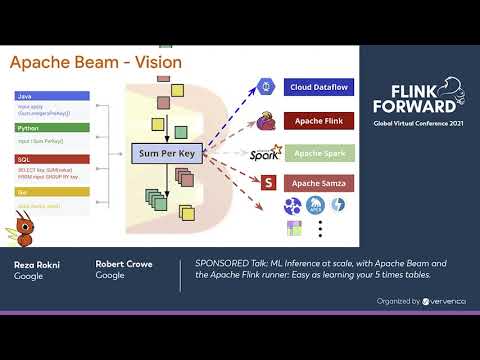
ML Inference at scale, with Apache Beam and the Flink runner: Easy as learning your 5 times tables.
Build a Real-time Stream Processing Pipeline with Apache Flink on AWS - Steffen Hausmann
Scaling stream data pipelines - Till Rohrmann & Flavio Junqueira
Taking Stateful Stream Processing to the Next Level with Kafka and Flink - Kafka Summit London 2018
How to keep our flock happy with Apache Flink on AWS - Henri Heiskanen
Enrico Canzonieri, Yelp, Inc. | Flink Forward 2018
Running Large Scale Kafka Upgrades at Yelp with Manpreet Singh | Bay Area Apache Kafka® Meetup
Building an End-to-End Analytics Pipeline with PyFlink
Building a Self-Serve Stream Processing Platform with Flink
Real-time Stream Analytics and Scoring Using Apache Flink, Druid & Cassandra - Ciesielczyk & Zontek