Flink Forward 2015: Maximilian Michels – Training DataSet API Hands On and FlinkML
Flink Forward 2015: Michael Häusler – Everyday Flink
Flink Forward 2015: Stefano Bortoli & Flavio Pompermaier – A Semantic Big Data Companion
Universal Machine Learning with Apache Beam - Maximilian Michels & Robert Bradshaw
Distributed Stream processing - Filtering, Joins and Windowing With Maximilian Michels
Flink Forward 2015: M. Schwering – Flink with MongoDB to enhance relevancy in personalization
Flink Batch Basics Presentation
Flink Forward 2015: Marton Balassi – Stateful Stream Processing
Flink Forward 2015: William Vambenepe – Google Cloud Dataflow and Flink
Flink Forward 2015: Fabian Hueske – Training Intro & System Setup
Flink Forward 2016: Till Rohrmann - Dynamic Scaling - How Apache Flink adapts to changing workloads
Apache Flink Worst Practices - Konstantin Knauf
#bbuzz: Maximilian Michels - When Code Is Not Enough: A Guide to Building an Open-Source Community
Flink Forward 2016: Fabian Hueske - Taking a look under the hood of Apache Flink’s relational APIs
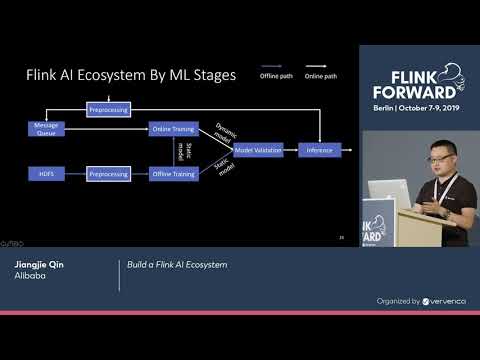
Build a Flink AI Ecosystem - Jiangjie Qin
Cypher-based Graph Pattern Matching in Apache Flink - Max Kießling & Martin Junghanns
#FlinkForward SF 2017: Kenneth Knowles - Portable stateful big data processing in Apache Beam
How Lyft built a streaming data platform with Flink on Kubernetes - Micah Wylde
View from Apache Flink on Evolution & Outlooks for the Modern Stateful Stream Processor | Ververica
Automating Flink Deployments to Kubernetes - Marc Rooding & Niels Dennissen