Accelerate and Autoscale Deep Learning Inference on GPUs with KFServing - Dan Sun
Serverless Machine Learning Inference with KFServing - Clive Cox, Seldon & Yuzhui Liu, Bloomberg
What is KFserving?
How We Built an ML inference Platform with Knative - Dan Sun, Bloomberg LP & Animesh Singh, IBM
Auto Scaling GPU Based ML Workloads to 2Mn+ req/day on HashiCorp Stack
How to Deploy Models at Scale with GPUs | TransformX 2022
Building Machine Learning Inference Through Knative Serverless...- Shivay Lamba & Rishit Dagli
Bristech MLOps: Clive Cox - ML Serving with KFServing (Sept 2020)
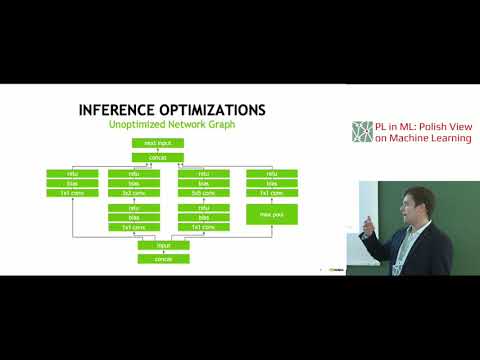
Piotr Wojciechowski: Inference optimization techniques
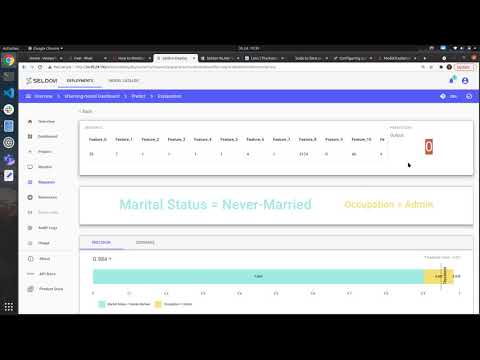
Seldon Deploy and KFServing: Serverless Deployment of Machine Learning Models
Serving Machine Learning Models at Scale Using KServing - Animesh Singh, IBM
Vertical Autoscaling of GPU Resources for Machine Learning in the Cloud
Optimizing Inference for Neural Machine Translation using Sockeye 2
Accelerate Federated Learning Model Deployment with KServe (KFServing) - Fangchi Wang & Jiahao Chen
Auto Scaling GPU Based ML Workloads to 2 million+ requests per day on HashiCorp Stack
Introducing KFServing: Serverless Model Serving on Kubernetes - Ellis Bigelow & Dan Sun
Kubeflow inference on knative — Dan Sun, Bloomberg
GPU as a Service Over K8s: Drive Productivity and Increase Utilization - Yaron Haviv, Iguazio
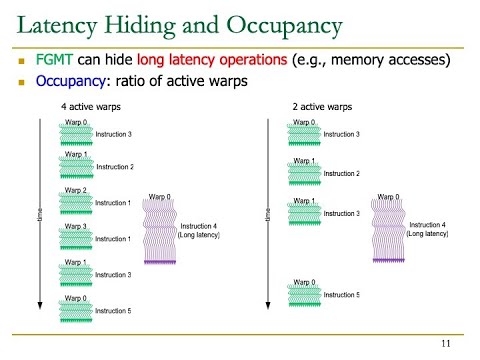
Heterogeneous Systems Course: Meeting 5: GPU Performance Considerations (Fall 2021)
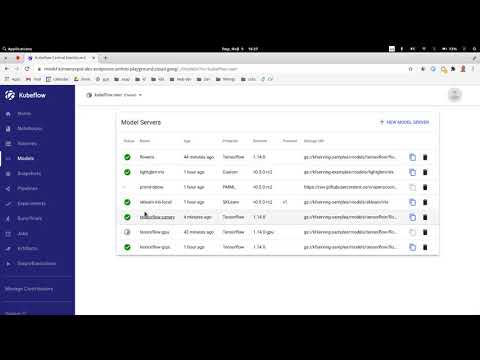
KFServing Proposed UI - demo